Resumen: Este capítulo expone en qué consiste el análisis espectral del sonido. Muestra que la duración del fragmento sonoro condiciona la capacidad de resolución del análisis. Así mismo, explica cómo se construye un espectrograma sonoro y con ayuda de algunos ejemplos realizados con Matlab presenta varios aspectos del sonido musical que se pueden estudiar mediante ellos.
Introducción
En los capítulos anteriores hemos visto mediante el osciloscopio virtual distintos ejemplos de señales de audio, es decir, de la forma que adquiere la vibración sonora a lo largo del tiempo. Estas señales nos han ayudado a distinguir los rasgos característicos de los sonidos musicales y la manera en la que nosotros los percibimos. Hemos podido comprobar que, en líneas generales, nuestra sensación auditiva no es capaz de seguir el rápido movimiento de la vibración sonora, sino que atiende principalmente a los parámetros de frecuencia y amplitud de los componentes que forman el sonido musical.
En efecto, como veremos más adelante, nuestra percepción descompone el movimiento vibratorio que llega a nuestro oído, de modo que obtiene la frecuencia y la amplitud de sus componentes sinusoidales. Por eso, para estudiar la realidad musical de una forma completa necesitamos una herramienta de análisis que nos permita descomponer los sonidos en sus componentes sinusoidales y extraer sus parámetros de frecuencia y amplitud (salvo circunstancias excepcionales, podemos ignorar la fase inicial). Nos interesa pasar de una representación de la vibración en su desarrollo temporal a una representación de la vibración en función de la amplitud de los componentes que la constituyen o, dicho en términos más técnicos, pasar de la representación en el dominio del tiempo a la representación en el dominio de la frecuencia. Esta tarea se realiza mediante las técnicas de análisis espectral, llamado también análisis frecuencial. En este capítulo me propongo explicar qué es el análisis espectral del sonido, en particular, en el caso del sonido musical.
Hoy en día disponemos de algoritmos numéricos muy potentes que nos permiten realizar el análisis de los sonidos y extraer la frecuencia y la amplitud de cada componente simple, los cuales pueden ser realizados con facilidad en un ordenador. La Fast Fourier Transform (FFT) es capaz de descomponer un fragmento de señal en sus componentes sinusoidales con gran eficacia. Pero me ha parecido que explicar en qué consiste la Transformada de Fourier se alejaba del propósito de este curso. En su lugar, creo que es más intuitivo, y no menos correcto, explicar el análisis frecuencial utilizando el fenómeno de la resonancia. De hecho, hasta el desarrollo de las técnicas digitales los analizadores de espectro tradicionales consistían en una batería de circuitos resonadores que medían la amplitud de cada componente presente en la señal.
Por otra parte, explicar el procedimiento del análisis frecuencial a partir del fenómeno de la resonancia tiene la ventaja, a mi juicio, de que es más fácil de asimilar para un lector sin conocimientos físicos ni matemáticos. Además, puesto que nuestro sistema auditivo procede de una manera similar, este punto de vista nos va a permitir entender mejor la forma en la que percibimos las frecuencias de los componentes que constituyen los sonidos, la cual se produce por la localización de sus resonancias en los diferentes puntos de la membrana basilar situada en nuestro oído interno.
El análisis espectral se utiliza habitualmente para sonidos o fragmentos musicales que constan de múltiples componentes, por lo que es necesario conocer hasta qué punto va a ser capaz de distinguirlos y localizarlos con precisión en el caso de que esos componentes tengan frecuencias próximas. Veremos a lo largo de este capítulo que la capacidad de resolución del análisis espectral está indisolublemente ligada a la duración del fragmento analizado, de modo que si queremos un análisis preciso y exacto deberemos elegir una duración larga. El problema surge porque, en general, a menos que lo que se pretenda sea obtener una especie de valor promediado útil en algunas circunstancias, es necesario que los parámetros de los componentes permanezcan estables durante el tiempo en el que se efectúa el análisis. Pero en el caso de los sonidos musicales reales, aunque son mucho más estables que los del habla, generalmente la estabilidad no se mantiene más allá de unos 50 milisegundos, por lo que, salvo circunstancias excepcionales, la longitud del fragmento no debe ser mucho mayor que esa cantidad, de forma que podamos considerar, aunque sólo sea de forma aproximada, que los parámetros han permanecido constantes durante el intervalo de tiempo analizado.
En este capítulo veremos, en primer lugar, en qué consiste el análisis espectral y cómo se puede realizar mediante el fenómeno de la resonancia. Después estudiaremos la cuestión esencial de los límites de su capacidad de resolución. A continuación veremos cómo mediante el espectrograma es posible obtener una representación de la evolución de los distintos componentes simples a lo largo del tiempo. Por último, para ejemplarizar las ideas expuestas y para preparar la utilización de esta nueva herramienta en el estudio de los sonidos reales, presentaré los espectrogramas de varios sonidos característicos.
Un modelo ideal de analizador espectral mediante resonancias
Imaginemos que disponemos de un piano ideal en el que las cuerdas vibran con toda facilidad, pues no hay apagadores. Además, las cuerdas de este piano imaginario sólo tendrían un modo de vibración, el modo fundamental, es decir, sólo resonarían cuando la frecuencia que las excitara coincidiera con su frecuencia natural o estuviera próxima a ella. Las cuerdas de este piano imaginario, en lugar de estar espaciadas siguiendo la escala cromática, estarían separadas de hercio en hercio (aunque también podrían haber estado separadas de décima de hercio en décima de hercio o de cualquier otra forma). Evidentemente este piano imaginario poseería miles de cuerdas, tantas como quisiéramos. Lo que acabo de describir será nuestro analizador espectral ideal.
Delante de este piano haremos sonar, imaginariamente claro está, los sonidos que vayamos a analizar y luego mediremos la amplitud con la que vibra cada una de las cuerdas que se han quedado resonando, representando los resultados en una gráfica.
En las gráficas de componentes frecuenciales que presentaré a partir de ahora consideraremos que cada uno de los pequeños “palitos” que las constituyen corresponde a una cuerda de nuestro piano imaginario. La altura que alcance cada uno de esos palitos reflejará la amplitud relativa con la que se ha quedado resonando la cuerda correspondiente, en una escala que va del 0 al 1. He asociado, de manera similar a las gráficas del capítulo 7, un color a cada amplitud, dentro de una escala que se corresponde con la de los colores por los que pasa el hierro al calentarse: el cero será el negro absoluto; los valores próximos a cero serán de un rojo muy oscuro; progresivamente, conforme los valores se incrementen, el rojo pasará a ser más brillante; luego el rojo se transformará en amarillo; y finalmente, a medida que los valores se van aproximando al 1, el amarillo se irá aclarando hasta llegar al blanco absoluto, que representará el valor máximo, el 1.
Supongamos que delante de nuestro imaginario piano hacemos sonar durante un segundo de duración un sonido simple de 220 Hz, un la3 formado por un único componente. La elección de un segundo no ha sido algo casual, pues, como veremos en el apartado siguiente, la duración del fragmento sonoro puede condicionar en determinadas circunstancias la fiabilidad del análisis. La duración temporal que se elige recibe habitualmente el nombre de “ventana de observación” o “ventana de análisis”.
Ahora nos interesa comprobar cómo responde este analizador de espectro ideal al sonido propuesto y averiguar si localiza bien la frecuencia. La gráfica de abajo representa las amplitudes de las cuerdas que quedarán resonando en el piano ideal. He limitado la gráfica a la representación de los primeros 1.000 Hz.

Observamos en esta gráfica un pico muy destacado pintado de un color amarillo muy luminoso, próximo al blanco, situado a la derecha de la cuadrícula que señala los 200 Hz. Este pico correspondería a la cuerda del piano imaginario que se ha quedado resonando con más fuerza y, en principio, coincidiría con el componente sinusoidal que, como ya sabemos, constituye el sonido que estamos analizando. El valor absoluto de su amplitud no nos interesa ahora, pues este parámetro sólo es pertinente cuando hay más de un componente, pues permite comparar las diferentes amplitudes.
Veamos un detalle de la zona que rodea a este componente, algo así como si hiciéramos un zoom positivo sobre la gráfica.

Ahora distinguimos con claridad la representación de cada una de las cuerdas del piano que han quedado resonando. Apreciamos que la cuerda que resuena con más fuerza es la de 220 Hz. Pero, como podemos observar en la gráfica, al estar las cuerdas de este piano separadas de hercio en hercio, en realidad solo podemos saber que la frecuencia del componente del sonido analizado habrá sido mayor que 219,5 Hz y menor que 220,5. En efecto, el margen de precisión de nuestro piano analizador de espectro es de un hercio, aunque nada nos habría impedido añadir en medio muchas más cuerdas a este piano imaginario y obtener la precisión que deseáramos.
Así pues, de este análisis se desprende que el componente presente en el sonido que estamos analizando se corresponde con el pico destacado en la gráfica de las amplitudes de las cuerdas resonantes. Pero eso no es todo. También observamos que, en menor medida, algunas de las cuerdas laterales han obtenido cierta amplitud. Esto parece intuitivamente coherente, pues el efecto de la resonancia también hace vibrar las cuerdas cuya frecuencia es muy próxima a la del componente del sonido que estamos analizando.
Cada una de las cuerdas de este hipotético piano resonará cuando en el sonido que queramos analizar esté presente un componente sinusoidal muy próximo a su frecuencia natural de vibración. En este caso la cuerda que resonará con más fuerza será aquella que tenga una frecuencia natural lo más cercana a 220 Hz; pero las cuerdas próximas, como es fácil de intuir, también resonarán, aunque sea en menor medida. Estas cuerdas vibrarán también a la frecuencia de ese componente, en este caso, a 220 Hz, con independencia de la frecuencia exacta a la que cada una de ellas esté afinada. La amplitud con la que vibren las cuerdas irá incrementándose conforme su frecuencia natural sea más cercana a la del componente. Por eso en las gráficas nos encontramos con que no aparece sólo un palito en la frecuencia de los 220 Hz, sino que a ambos lados hay otras cuerdas/frecuencias que van decrementando su amplitud a medida que su frecuencia natural de vibración se aleja de la que está sonando. No obstante, en principio, esto no parece alterar la fiabilidad del resultado.
Relación entre duración temporal y resolución frecuencial
Ahora bien, la pregunta es: ¿Siempre esto es así? ¿Todo resulta tan fácil? ¿Disponemos, o mejor dicho, dispone la naturaleza de un medio tan sencillo para determinar con precisión los componentes sinusoidales presentes en cualquier fragmento sonoro? La respuesta, desafortunadamente, es que no. Voy a realizar ahora el análisis del mismo sonido de un solo componente de 220 Hz, pero acortando la duración del fragmento a analizar: ahora haré sonar delante de nuestro piano imaginario sólo 50 milésimas de segundo (es decir, la ventana de análisis será de 0,05 s). Veamos lo que ocurre en la gráfica de abajo.

Ahora observaremos un detalle de la zona entre 160 Hz y 280 Hz.

Comprobamos ahora que, al reducir la cantidad de tiempo de la señal analizada, el número y la importancia de las cuerdas laterales afectadas ha sido mucho mayor que cuando analizábamos un segundo entero. Esto responde también a una cierta idea intuitiva sobre la resonancia, pues todos hemos podido comprobar que el efecto de la resonancia se aprecia más fácilmente cuando la señal que excita dura más tiempo. Por lo tanto, vemos que la duración de la vibración analizada determina el número de cuerdas próximas afectadas por la resonancia. Dicho de otra manera, el efecto de la resonancia es más picudo conforme la duración del sonido que la provoca es mayor.
Si se trata, como en este caso, de analizar un componente aislado no se plantea ningún problema. Pero, ¿qué hubiera ocurrido si hubiéramos querido analizar una señal con dos componentes que estuvieran próximos? Vamos a comprobarlo en los dos ejemplos siguientes.
En el primero voy a analizar una señal formada por dos componentes sinusoidales de la misma amplitud. La frecuencia del primero, igual que antes, es de 220 Hz (la3), y la del segundo, de 233 Hz (sib3). La ventana de análisis (la duración del fragmento analizado) será, como en el ejemplo anterior, de sólo 50 ms. Realicemos el análisis y veamos los resultados.

Comprobamos que el análisis efectuado con este tamaño de ventana ha sido incapaz de distinguir los dos componentes, el de 220 Hz y el de 233 Hz, que sabemos que existen en la señal a analizar, y que, en su lugar, ha salido un solo componente cuya frecuencia es la media aritmética de los otros dos, 226,5 Hz. Ciertamente, si hubiéramos podido analizar un segundo entero de duración no habríamos tenido ningún problema para distinguir nítidamente los dos componentes. En la siguiente gráfica podemos ver el resultado de realizar el mismo análisis durante un segundo de duración.

En efecto, aquí los dos componentes han sido resueltos y además con toda la precisión que había requerido al análisis.
Veamos ahora otro ejemplo de dos componentes un poco más separados. Vamos a analizar una señal constituida por un componente de 220 Hz (la3) y otro de 262 (do4). La duración del análisis va a ser también de 50 ms.

En este caso el análisis sí que ha sido capaz de distinguir los dos componentes. Ahora bien, si nos fijamos en la localización de los picos máximos vemos que el componente de 220 Hz ha sido desplazado a 232 Hz y el de 262 Hz a 250 Hz. Es decir, observamos que la presencia de un componente próximo altera de manera notable la fiabilidad del resultado obtenido.
Resumiendo, nos encontramos con que al reducir el tamaño de la ventana de análisis disminuye su capacidad para discernir componentes distintos y la precisión con la que puede determinar su frecuencia. Este problema plantea una cuestión esencial: si queremos obtener una buena resolución en frecuencia necesitamos una duración temporal larga. Pero la realidad es que el sonido musical va evolucionando con el tiempo y los parámetros de sus componentes solamente permanecen relativamente estables durante un tiempo pequeño, unas cincuenta milésimas de segundo.
Así pues, a la hora de efectuar un análisis frecuencial de un fragmento musical siempre hemos de buscar una opción de compromiso. Podremos utilizar una ventana de mayor duración, pero en ese caso tendremos que asumir que lo que obtendremos en el análisis será una especie de promediado de la evolución de los acontecimientos sonoros que se hayan producido en ese tiempo. Podremos elegir una ventana de corta duración para garantizar que el fragmento analizado sea suficientemente estable, pero en ese caso deberemos asumir que si coinciden componentes próximos puede que el análisis no sea capaz de distinguirlos o al menos que pierda precisión en su localización.
El espectrograma
Como he dicho ya, los parámetros de los componentes sonoros en los sonidos reales no suelen permanecer estables, sino que evolucionan a lo largo de su duración. Por ello, para analizar un fragmento sonoro nos interesará muchas veces obtener una representación que muestre la evolución de los valores de amplitud y de frecuencia de cada componente durante el tiempo que dura el sonido. Habitualmente esta representación recibe el nombre de espectrograma.
Un espectrograma no es otra cosa que una forma de representar gráficamente los sucesivos y solapados análisis frecuenciales que se pueden hacer a lo largo de un sonido o de un fragmento de una interpretación. Esta forma de representación guarda mayor afinidad con la manera en la que nosotros oímos que la representación de la señal de audio que hemos visto en el osciloscopio.
En los vídeos en los que se simulaba un osciloscopio y en las gráficas en las que se mostraba el desplazamiento de la vibración en relación al tiempo hemos tenido una representación puramente temporal del hecho físico de la vibración. Acabamos de ver también en qué consiste una representación puramente frecuencial, donde no importa cuándo se han producido los componentes sonoros, sino sólo su frecuencia y su amplitud relativa. Ahora bien, ninguna de estas dos formas coincide con la manera en la que oímos. Oímos frecuencias, pero oímos frecuencias que cambian en el tiempo, bien porque unas dejan de sonar y surgen otras, bien porque las que estaban sonando evolucionan en amplitud, o bien porque desparecen y surgen otras frecuencias. No obstante, en lo que concierne al sonido musical, hay cierto margen de tiempo en el que las cosas, salvo momentos especiales de transición, parecen cambiar poco, es decir, hay momentos en el que se puede considerar que la vibración es casi estable, pues los componentes y sus parámetros no han sufrido grandes cambios. Como he dicho al principio de este capítulo, el tamaño que se suele considerar adecuado para este intervalo temporal viene a ser de unas 50 milésimas de segundo. Si cada 50 ms se va haciendo un análisis que va progresivamente desplazándose en el tiempo y solapándose, la evolución de los parámetros será más fiable y responderá más a la realidad que si se hace un análisis en intervalos más grandes o más pequeños.
Mediante el vídeo que pongo a continuación voy a explicar más detenidamente cómo podemos obtener un espectrograma. Voy a utilizar para este ejemplo los primeros compases del adagio de la Sonata para violín solo de J. S. Bach (BWV 1001). Para facilitar la presentación, he limitado la banda de los componentes a los primeros 2.000 Hz. Veamos primero el vídeo.
Recomiendo ir parando el vídeo en el momento que se considere oportuno para entender mejor lo que sucede. Encontraremos una imagen similar a la siguiente.
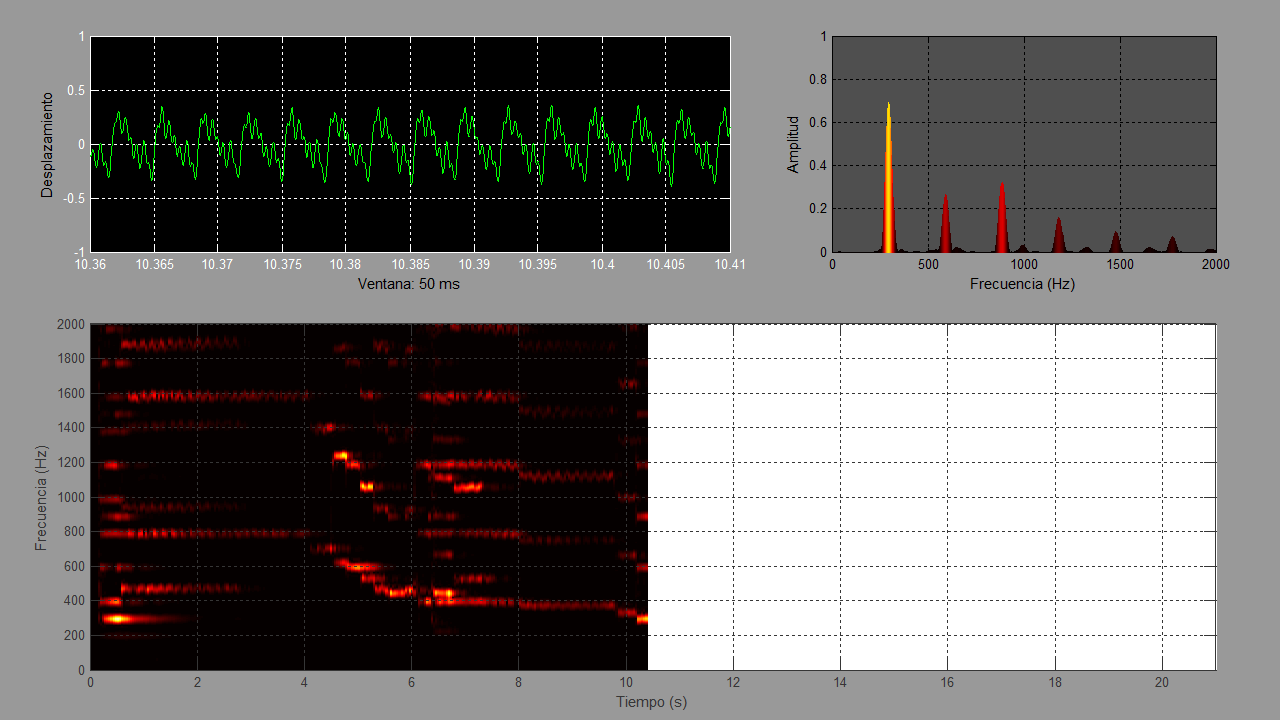
En el panel de la izquierda tenemos la representación temporal de la vibración a modo de osciloscopio, es decir, la forma de la vibración a lo largo del tiempo. Al estar en la figura 9 la imagen detenida, he podido añadir la localización temporal precisa: el fragmento de señal analizado en este cuadro del vídeo corresponde al intervalo de tiempo transcurrido entre el segundo 10,360 y el 10,410. En total son las 50 milésimas de segundo que constituyen la duración de los fragmentos que analizamos. Podemos observar que en esta ocasión la forma de la vibración ha permanecido casi prácticamente estable durante ese intervalo de tiempo. Sin embargo, si hubiéramos detenido el vídeo en algún otro momento, especialmente en el ataque de alguna nota, nos hubiéramos encontrado con una situación más inestable.
En el panel de la derecha tenemos la representación frecuencial, es decir, los componentes que constituyen la señal que estamos viendo en el panel de la izquierda. Esta representación sigue los mismos criterios que acabamos de ver en los apartados anteriores, es decir, muestra el análisis frecuencial. He aumentado proporcionalmente la amplitud para que en el espectrograma inferior resaltaran más los componentes pequeños. En esta ocasión vemos que aparecen destacados 6 picos que corresponden a los 6 primeros armónicos de la nota re4, cuya frecuencias son, redondeando en hercios: 294,7 Hz, 587,4 Hz, 881,1 Hz, 1174,8 Hz, 1.468,5 Hz, 1.762,2 Hz. Las amplitudes están también acompañadas de una escala de colores, como la que he descrito antes. El componente primero se ve claramente destacado y el pico presenta un color amarillo luminoso que se aproxima ya al blanco. Los componentes segundo y el tercero tienen también una amplitud considerable y su color es un rojo brillante, siendo ligeramente mayor el tercero que el segundo. Los componentes cuarto, quinto y sexto van progresivamente perdiendo amplitud y sus colores van siendo cada vez más oscuros. A lo largo del vídeo podemos ver como esta gráfica va evolucionando siguiendo los cambios en el sonido. Dicho de otra manera, conforme el sonido va pasando por el panel izquierdo, la representación frecuencial de la derecha se va actualizando.
En el panel de abajo vemos cómo se va construyendo el espectrograma del fragmento. Si nuestro reproductor de vídeo nos permite avanzar de cuadro en cuadro veremos que en cada cuadro tenemos un desplazamiento de la señal hacia la izquierda en la ventana temporal del panel de la izquierda, una actualización de su representación frecuencial en el panel de la derecha y, por último, una nueva columna de píxeles en el panel inferior. Esa nueva columna de píxeles presenta los valores frecuenciales correspondientes al análisis frecuencial del cuadro que estamos analizando, utilizando simplemente los mismos colores que hemos obtenido en la representación frecuencial, de tal forma que aquí prescindimos de la longitud del componente y la representamos únicamente por el color.
Así por ejemplo, si en el visor de imágenes con el que estamos examinando esta gráfica hacemos un zoom considerable, hasta el extremo de poder ver píxeles aislados, y nos fijamos únicamente en la última columna de píxeles del espectrograma que estamos construyendo y que hemos detenido, veremos que los picos que hemos visto en el panel de las frecuencias se corresponden, con sus mismos colores, con los píxeles que vemos destacados en esta último columna de la imagen. Tal vez el componente más agudo nos aparezca un poco desvaído, pero aun con todo nos resultará fácil ver cómo esta columna de píxeles se corresponde y representa la amplitud de cada componente frecuencial analizado en el panel de la derecha.
Esta forma de representación nos permite dejar un rastro de lo que hemos visto que ha ido sucediendo a lo largo del tiempo en el panel de las frecuencias. De este modo tenemos una representación frecuencial actualizada con el paso del tiempo. Y esto es ya similar a la manera en la que nosotros oímos y a la que en la realidad se producen la mayor parte de los acontecimientos sonoros. Así pues, el espectrograma es la forma de representación más idónea del sonido de un fragmento musical.
Interpretación de los espectrogramas
Voy a presentar a continuación varios espectrogramas para mostrar cómo podemos interpretar las imágenes que ofrecen. Utilizaré los mismos ejemplos sonoros que hemos visto en anteriores capítulos, lo cual nos permitirá comparar la información que nos proporciona el espectrograma con la que obteníamos en el osciloscopio. He confeccionado mediante Matlab varios vídeos para facilitar el seguimiento del sonido en el espectrograma. La imagen del vídeo muestra el espectrograma del fragmento completo, mientras la línea verde vertical se va desplazando marcando el instante que está sonando. Todos los espectrogramas presentan sólo los primeros 4.000 Hz.
Espectrograma de sonidos armónicos estables
Comenzaré con el espectrograma que corresponde al vídeo de la figura 4 del capítulo 7, donde se muestra cómo la incorporación de los sucesivos componentes armónicos aproxima la forma de la vibración a la de un diente de sierra y cómo repercute esta incorporación en la cualidad sonora. En este ejemplo suena ocho veces la misma nota, un la3 a 220 Hz. Empieza sonando el componente fundamental aislado, un sonido simple de 220 Hz, y luego se van incorporando sucesivamente todos los componentes de la serie armónica, hasta llegar al octavo armónico.
En este espectrograma podemos observar que cada componente aparece representado por una línea horizontal, lo que indica que la frecuencia de todos ellos permanece constante durante la emisión de cada nota. Así mismo, por el color podemos apreciar que la amplitud de cada componente es la misma en todas las repeticiones de la nota en las que está presente, y también que la amplitud de los componentes que van apareciendo es progresivamente menor. Así vemos que el primer armónico o fundamental presenta la mayor amplitud, pues su color es casi blanco, que el color con el que está representado el segundo armónico es amarillo dorado y que los siguientes son rojos cada vez más oscuros.
Podemos ver también en el espectrograma con total claridad la estructura armónica que forman el conjunto de los componentes de la nota, pues todos ellos están separados entre sí por la misma distancia, una distancia que coincide con la frecuencia del primer componente.
Espectrograma de sonidos armónicos cuyos componentes cambian de amplitud
Veamos ahora cómo queda reflejado en un espectrograma la evolución en amplitud de los componentes armónicos de un sonido. He elegido tres sonidos cuya forma de vibración ya habíamos examinado en el capítulo 9, cuando estudiábamos las envolventes de amplitud. En todos los ejemplos los sonidos están formados por los cuatro primeros armónicos y su frecuencia fundamental es 220 Hz, correspondiente a la nota la3. En el primer caso se produce un retraso en el momento del ataque de los componentes superiores (figura 3 del capítulo 9); en el segundo hay cambios en las amplitudes respectivas de cada componente durante el mantenimiento del sonido (figura 4 del capítulo 9); y en el tercero ocurre que los componentes superiores se extinguen mucho más rápidamente que los inferiores (figura 2 del capítulo 9).
A diferencia de la representación de la señal en el tiempo que veíamos en el osciloscopio, donde no podíamos distinguir los componentes individuales, este espectrograma nos muestra de forma clara la evolución de la amplitud de cada componente que forma el sonido. En primer lugar podemos observar que en todos los casos estamos ante un sonido armónico, pues las distancias entre los componentes son iguales. Por otro lado, los cambios en el color de cada componente a lo largo de su duración nos indican que ha variado su amplitud. En el espectrograma se puede distinguir también el carácter más o menos abrupto del ataque y de la extinción de las notas.
Si pasamos a analizar caso por caso, nos encontramos con que en el primer sonido la amplitud de los componentes superiores es progresivamente menor, pues vemos que el componente primero es el que presenta mayor luminosidad, mientras que el último es el más oscuro. Se aprecia también claramente en el momento del ataque un retraso de los sucesivos componentes, siendo el fundamental el primero que entra. Por el contrario, vemos que en la extinción del sonido todos los componentes se apagan simultáneamente (si bien los componentes de mayor amplitud parecen prolongarse un poco más, esto se debe solamente a que los colores más oscuros se funden antes con el negro). Vemos también que las líneas que representan los componentes cambian de color durante la parte inicial del sonido, aproximadamente en la primera décima de segundo, desde un rojo muy oscuro que se funde casi con el negro del fondo, hasta llegar al color que mantendrán durante la mayor parte de la emisión. Esto es indicativo de que el ataque de la nota ha sido más bien suave, tal como apreciamos al oírla. Así mismo, en la etapa final de la nota vemos que los componentes van perdiendo luminosidad, lo que hace que parezca que se vayan adelgazando. Esto corresponde a la extinción suave que oímos.
En el segundo sonido los ataques de los componentes son simultáneos y menos suaves que en el primero, como podemos observar en el hecho de que se alcanza más rápidamente el color que mantendrá cada componente durante la emisión. Así mismo, vemos que la forma en la que se extinguen es similar a la del sonido primero. Los cambios de color que observamos durante su etapa intermedia nos indican que la amplitud de los componentes superiores, en especial el segundo y el tercero, se va haciendo progresivamente mayor, hasta superar, aproximadamente a la mitad de la duración del sonido, a la del fundamental; luego vemos que se invierte la tendencia y se recupera la situación inicial. Esto coincide con el cambio de cualidad sonora que apreciamos: el sonido comienza con un carácter más bien suave, va ganando cuerpo y un poco de aspereza, y finalmente retorna a la suavidad.
En el tercer caso, como en el primero, la representación de los componentes es progresivamente más oscura, lo que nos indica que su amplitud es menor conforme mayor es su frecuencia. Cada uno de los componentes tiene mayor intensidad lumínica al inicio de la emisión de la nota y luego se oscurece hasta casi desaparecer. Podemos ver en el espectrograma que los cuatro componentes han surgido a la vez. Por el contrario, la extinción se ha realizado de forma claramente desfasada, de tal modo que al final sólo queda sonando el componente fundamental, como podemos ver por la desaparición de las líneas que representan cada componente en el espectrograma. Si nos fijamos un poco más, vemos que el ataque abrupto que oímos se traduce en una línea vertical en el espectrograma, que se extiende por arriba y por abajo de la posición del respectivo componente y que luego, en forma de una especie de embudo, va a desembocar en la línea que le corresponde por su frecuencia. Esto se debe a que el ataque abrupto es similar al ruido, es decir, contiene una banda muy amplia de frecuencias. Podemos ver que la inestabilidad inicial es ruidosa y pasa cierto tiempo hasta que el sonido alcanza la estabilidad. Cuando veamos sonidos reales, los ataques abruptos vendrán caracterizados por esa forma de embudo que desemboca en la zona más luminosa del componente.
Espectrograma de sonidos cuyos componentes modifican su frecuencia
A continuación vamos a ver un conjunto de casos en los que podremos apreciar cómo se observa la evolución de la frecuencia en un espectrograma. Los sonidos son los mismos que los que utilicé en el capítulo 9 al explicar la envolvente de frecuencia. Los tres primeros sonidos corresponden a la figura 5 y los otros dos a la figura 6.
Al igual que en los ejemplos anteriores y a diferencia de la representación de la señal en el tiempo, el espectrograma nos permite apreciar la evolución de cada componente por separado.
En el primer caso observamos un componente aislado que mantiene constante su frecuencia, como podemos ver por su horizontalidad. En el segundo, vemos unas oscilaciones que reflejan perfectamente el vibrato que oímos. En él podemos apreciar que la profundidad del vibrato aumenta y luego disminuye, pues las ondulaciones se hacen más pronunciadas y luego menos, aunque vemos también que el ritmo de las oscilaciones —es decir, la frecuencia del vibrato— permanece constante. En el tercer sonido apreciamos un incremento significativo de la frecuencia tras el ataque, que luego baja de nuevo hasta alcanzar el nivel correspondiente en el que ya se mantiene horizontal. En el cuarto caso tenemos un sonido formado por tres componentes armónicos que mantienen su frecuencia constante, como podemos apreciar en su horizontalidad. Y en el quinto, vemos los mismo tres componentes anteriores, pero ahora con un vibrato similar al del segundo sonido. En él podemos apreciar que las ondulaciones del segundo componente son el doble de profundas que las del primero y que las del tercero son el triple que las del primero, como era lógico de esperar, pues los sonidos siguen siendo armónicos durante el vibrato.
Espectrograma de ruido blanco y sonido simple
Una vez visto cómo se pueden observar en un espectrograma los componentes y la respectiva evolución de sus parámetros de frecuencia y amplitud, vamos a examinar un elemento que también está presente de una u otra manera en los sonidos musicales: el ruido. Para ver cómo aparece representado el ruido en un espectrograma y cómo se distingue inmediatamente de un sonido musical voy a utilizar el ejemplo de la figura 1 del capítulo 3, donde veíamos la representación en el osciloscopio del ruido blanco, aquél que contiene todas las frecuencias del espectro, y de su opuesto, un sonido simple.
La representación espectral del ruido blanco es el granulado de la izquierda, mientras que la línea blanca de la derecha corresponde al sonido simple. Si hubiéramos extendido la representación del espectrograma más allá de los 4.000 Hz hubiéramos seguido observando ese mismo granulado en toda la franja audible. Idealmente un ruido blanco contiene todas las frecuencias con la misma amplitud, por lo que deberíamos haber visto, en lugar de este granulado, un rectángulo plano de un color uniforme. Pero la aleatoriedad absoluta sólo es posible en la idealidad. Para ello deberíamos haber dispuesto de una duración infinita y haber tenido una garantía total de que los números que hemos obtenido para generar el ruido blanco fueran perfectamente aleatorios, no pseudo-aleatorios, como los que hemos utilizado. Así mismo, cuando observamos el componente aislado, un sonido simple, deberíamos haber visto una línea infinitamente fina, la correspondiente solamente a esa precisa frecuencia. Sin embargo, en los espectrogramas siempre vemos para cada componente una línea con un cierto grosor. Estas son las aproximaciones con las que vamos a ver las señales en los espectrogramas que realicemos habitualmente.
Espectrograma de ruido de tráfico y de habla
Quiero ahora presentar un ejemplo en el que se toman dos situaciones de la vida real en las que no hay sonido musical. Ambos ejemplos corresponden también al capítulo 3: el primero consiste en la primera parte de la figura 4, que contiene ruido de tráfico en un día de lluvia, y el segundo en la primera parte de la figura 10 en el que una locutora de radio dice unas pocas palabras.
En la primera parte vemos con claridad el ruido blanco producido por la lluvia, que cubre todo el espectro de frecuencias de una manera homogénea. En la parte de abajo del espectro vemos una forma granulada, correspondiente también a ruido, pero que se sitúa en una zona de más bajas frecuencias. Es el ruido propio del tráfico. Vemos también como el motor de un coche, al acelerar, se refleja en la aparición de unos componentes que suben rápidamente su frecuencia. Y oímos en medio de ese ruido un sonido armónico, la bocina de un coche, como se puede apreciar con claridad por la distribución vertical de componentes igualmente espaciados que se observan en torno al segundo nueve y con menos claridad un poco antes del segundo 4.
En la segunda parte del espectrograma, cuando oímos hablar a la locutora, vemos una alternancia entre breves fragmentos de sonidos armónicos y un granulado organizado en barras verticales. Es la alternancia entre ruido y sonido armónico característica del habla, simplificando un poco, la alternancia entre consonantes y vocales. Vemos también que las vocales cambian de frecuencia siguiendo unos esquemas ascendentes y descendentes dentro de unos pequeños márgenes. Estos esquemas son los que constituyen la entonación del habla.
Conclusión
En este capítulo hemos estudiado cómo se puede descomponer una vibración cualquiera en la suma de los componentes sinusoidales que la constituyen, cada uno con su propia frecuencia y amplitud. Al hacer esto hemos obtenido una representación frecuencial del sonido analizado. Así mismo, dado que habitualmente los parámetros de los componentes armónicos que constituyen el sonido musical cambian a lo largo del tiempo, hemos visto que el espectrograma es una forma adecuada de representar esta evolución, pues muestra para cada instante la frecuencia y la amplitud de los componentes que forman el sonido.
- Capítulo siguiente: Capítulo 11. El timbre
- Capítulo anterior: Capítulo 9. Envolventes de amplitud y de frecuencia
4 comentarios:
Hola Soy Jesus H. Piña, médico, especialista en medicina interna y sordera...en la figura 8 donde dice ventana de 50 ms, no debiera decir "ventana de .05 ms"?... no entiendo cuando dice que es de 50 ms....gracias
Hola Jesús. Muchas gracias por tu interés. Yo creo que la diferencia está en que probablemente los médicos hagáis pruebas de impulso muy cortas, para ver si todo responde con rapidez. En estos espectrogramas musicales en los que se pretende reconocer las notas que suenan, si hubiera utilizado una ventana mucho más corta, incluso de 10 o 20 milésimas de segundo, se hubiera apoderado el tiempo a la frecuencia y la línea melódica se hubiera desdibujado. En compresión de sonidos utilizan también ventanas cortas de 2 a 5 milisegundos, pero probablemente sea en medicina donde trabajéis con ventanas incluso más cortas. Con esta ventana de 50 milisegundos se pierden los transitorios y en general los fenómenos de predominio temporal, pero se clarifican las frecuencias. La verdad es que la elección del tamaño de la ventana depende de lo que quieras observar.
Saludos,
Luis Colomer
Hola Luis, soy Gustavo estudiante de bajo y necesito saber si el espectrograma se aplica para instrumentos de viento al igual que en las cuerdas,dado que la onda no viaja de igual manera en ambos medios
Hola Gustavo. El espectrograma se puede aplicar a cualquier instrumento o voz. Lo que sí sucederá es que el resultado será distinto en cada caso. Puedes probar con cualquier editor de sonido que tenga la opción de realizar espectrogramas y verás el resultado. También puedes utilizar el progama Matlab que he adjuntado, aunque tal vez te resulte más lioso. Si lo que quieres es ver el espectrograma de una nota aislada elige una ventana larga (0.1 s o más). Si lo que quieres es ver la melodía pon una ventana más corta (0.08 s o un poco menos).
Luis
Publicar un comentario